자바 성능 튜닝 - Collection 관련 By starseat 2024-04-19 18:05:32 java/spring Post Tags [자바 성능 튜닝 이야기](https://product.kyobobook.co.kr/detail/S000001032977) 책을 읽고 정리한 내용 입니다. --- 데이터를 담아서 사용할때 대부분 Collection과 Map 인터페이스를 상속받는 객체를 많이 사용한다. 일반적으로 목록 데이터를 가장 담기 좋은 것이 배열이고, 그 다음으로 Collection 관련 객체들이다. 배열은 처음부터 크기를 지정해야 하지만 Collection 관련 객체들 대부분은 그럴 필요 없이 객체들이 채워질 때마다 자동으로 크기가 증가된다. # Collection 및 Map 의 이해 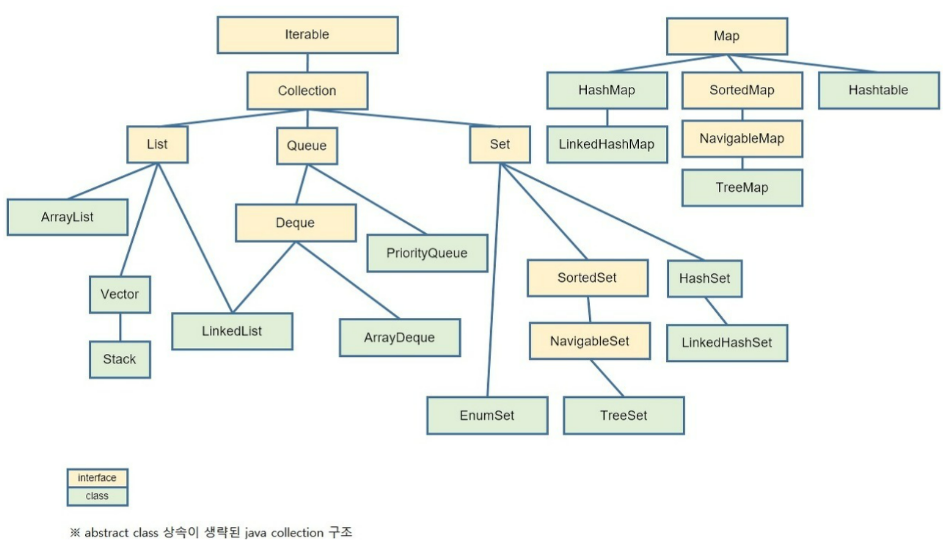 - **Collection**: 가장 상위 인터페이스 - **Set**: 중복을 허용하지 않는 집합을 처리하기 위한 인터페이스 - **List** - 순서가 있는 집합을 처리하기 위한 인터페이스 - 인덱스가 있어 위치를 지정하여 검색 가능 - 중복 허용 - List 인터페이스를 상속받는 클래스 중 **ArrayList** 가 가장 많이 사용됨. - **Map**: 키와 값의 쌍으로 구성된 객체의 집합을 처리하기 위한 인터페이스. (중복 허용 X) - **Queue**: 여러 개의 객체를 처리하기 전에 담아서 처리할 때 사용하기 위한 인터페이스 (FIFO, First In First Out) ## Set - Set 인터페이스는 중복 없는 집합 객체를 만들때 유용함. - Set 인터페이스를 구현한 클래스로는 **HashSet**, **TreeSet**, **LinkedHashSet** 이 있다. <br> - **HashSet**: 데이터를 해쉬 테이블에 담는 클래스로 순서 없이 저장 됨. - **TreeSet**: - `red-black` 이라는 트리에 데이터를 담음. - 값에 따라 순서가 정해짐 - 데이터를 담으면서 동시에 정렬을 하여 **HashSet** 보다 성능이 느리다. - **LinkedHashSet**: 해쉬 테이블에 데이터를 담으면서 저장된 순서에 따라 순서가 결정됨. ## List - List 는 간단하게 말하면 배열의 확장판 임. - List 인터페이스를 구현한 클래스들은 담을 수 있는 크기가 자동으로 증가됨. (C 나 java 의 배열은 최초 선언 시 사이즈 지정 필요) - 데이터의 개수를 확실히 모를때 유용하게 사용 됨. - 데이터가 많은 경우 처리 시간이 늘어난다는 단점이 있음. - List 인터페이스를 구현한 클래스로는 **Vector**, **ArrayList**, **LinkedList** 들이 있음. <br> - **Vector**: 객체 생성시 크기를 지정할 필요가 없는 배열 클래스 - **ArrayList**: **Vector**와 비슷하지만, 동기화 처리가 되어 있지 않음. - **LinkedList**: **ArrayList**와 동일하지만, **Queue** 인터페이스를 구현했기 때문에 FIFO 큐 작업 수행 ## Map - `Key` 와 `Value` 의 쌍으로 저장되는 구조체 - 그래서 단일 객체만 저장되는 다른 Collection API들과는 다르게 따로 분리되어 있음. - ID 와 패스워드, 코드와 명칭 등 고유한 값과 관련된 값을 보관할 때 유용. - Map 인터페이스를 구현한 클래스로는 **HashMap**, **TreeMap**, **LinkedHashMap** 이 있고, 원조 클래스 격인 **Hashtable** 클래스가 있음. <br> - **HashTable** - 데이터를 해쉬 테이블에 담는 클래스 - 내부에서 관리하는 해쉬 테이블 객체가 동기화 되어 있어, 동기화가 필요한 부분에서는 이 클래스를 사용해야 됨. - **HashMap** - 데이터를 해쉬 테이블에 담는 클래스 - **HashTable** 와 다른점은 `null 값을 허용`한다는 것과 동기화 되어 있지 않다는 것임. - **TreeMap** - `red-black` 트리에 데이터를 담음. - 키에 의해 순서가 정해짐. (`TreeSet` 과는 이 점이 다름) - **LinkedHashMap** - **HashMap** 과 거의 동일하며 이중 연결 리스트(doubly-linkedlist) 방식을 사용하여 데이터를 담음. ## Queue - 데이터를 담아 두었다가 먼저 들어온 데이터부터 처리하기 위해 사용 (FIFO, First In First Out) - **Queue** 인터페이스를 구현한 클래스는 두 가지로 나뉨. - java.util 패키지에 속하는 Queue(**PriorityQueue**) - java.util.concurrent 패키지에 속하는 클래스 <br> - **PriorityQueue**: 추가된 순서와 상관없이 먼저 생성된 객체가 먼저 나오도록 되어 있는 큐 - **LinkedBlockingQueue**: 저장할 데이터의 크기를 선택적으로 정할 수도 있는 FIFO 기반의 링크 노드를 사용하는 블로킹 큐 - **ArrayBlockingQUeue**: 저장되는 데이터의 크기가 정해져 있는 FIFO 기반의 블로킹 큐 - **PriorityBlockingQUeue**: 저장되는 데이터의 크기가 정해져 있지 않고, 객체의 생성 순서에 따라 순서가 저장되는 블로킹 큐 - **DelayQueue**: 큐가 대기하는 시간을 지정하여 처리하도록 되어 있는 큐 - **SynchronousQueue** - put() 메서드를 호출하면 다른 메서드에서 take() 메서드가 호출될 때까지 대기하도록 되어 있는 큐. (동기화) - 이 큐에는 저장되는 데이터가 없음 - API에서 제공하는 대부분의 메서드는 0이나 null 리턴함. <br> <span style="color: #7cafc2">- 블로킹 큐(blocking queue): 크기가 지정되어 있는 큐에 더이상 공간이 없을 때, 공간이 생길 때까지 대기하도록 만들어진 큐</span> # 성능 비교 ## Set **HashSet**, **TreeSet**, **LinkedHashSet** 의 성능 비교 ### SetAdd - 샘플 코드 ```java import java.util.*; import org.openjdk.jmh.annotations.*; @State(Scope.Thread) @BenchmarkMode({ Mode.AverageTime }) @OutputTimeUnit(TimeUnit.MICROSECONDS) public class SetAdd { int LOOP_COUNT = 1000; Set<String> set; String data = "abcdefghijklmnopqrstuvwxyz"; @GenerateMicroBenchmark public void addHashSet() { set = new HashSet<>(); // HashSet for(int i=0; i<LOOP_COUNT; i++) { set.add(data + i); } } @GenerateMicroBenchmark public void addHashSetWithInitialSize() { set = new HashSet<String>(LOOP_COUNT); // HashSet, 크기 지정 for(int i=0; i<LOOP_COUNT; i++) { set.add(data + i); } } @GenerateMicroBenchmark public void addTreeSet() { set = new TreeSet<>(); // TreeSet for(int i=0; i<LOOP_COUNT; i++) { set.add(data + i); } } @GenerateMicroBenchmark public void addLinkedHashSet() { set = new LinkedHashSet<>(); // LinkedHashSet for(int i=0; i<LOOP_COUNT; i++) { set.add(data + i); } } } ``` - 결과 | 대상 | 평균 응답 시간 (ms) | | -- | -- | | HashSet | 375 | | HashSetWithInitialSize | 352 | | TreeSet | 1,249 | | LinkedHashSet | 378 | ### SetIterate 데이터 읽을때의 성능 확인 - 샘플 코드 ```java import java.util.*; import org.openjdk.jmh.annotations.*; @State(Scope.Thread) @BenchmarkMode({ Mode.AverageTime }) @OutputTimeUnit(TimeUnit.MICROSECONDS) public class SetIterate { int LOOP_COUNT = 1000; Set<String> hashSet; Set<String> treeSet; Set<String> linkedHashSet; String data = "abcdefghijklmnopqrstuvwxyz"; String result = null; @Setup(Level.Trial) public void setUp() { hashSet = new HashSet<>(); treeSet = new TreeSet<>(); linkedHashSet = new LinkedHashSet<>(); for(int i=0; i<LOOP_COUNT; i++) { String temp = data + i; hashSet.add(temp); treeSet.add(temp); linkedHashSet.add(temp); } } @GenerateMicroBenchmark public void iterateHashSet() { Iterator<String> iter = hashSet.iterator(); while(iter.hasNext()) { result = iter.next(); } } @GenerateMicroBenchmark public void iterateTreeSet() { Iterator<String> iter = treeSet.iterator(); while(iter.hasNext()) { result = iter.next(); } } @GenerateMicroBenchmark public void iterateLinkedHashSet() { Iterator<String> iter = linkedH ashSet.iterator(); while(iter.hasNext()) { result = iter.next(); } } } ``` - 결과 | 대상 | 평균 응답 시간 (ms) | | -- | -- | | HashSet | 26 | | TreeSet | 35 | | LinkedHashSet | 16 | ### 랜덤 추출 단순 조회도 있지만 특정 Key 를 꺼내올 때도 있다. 테스트를 위해 `generateRandomSetKeysSwap()` 를 만들었다. - 샘플 코드 ```java import java.util.*; public class RandomKeyUtil { public static String[] generateRandomSetKeysSwap(Set<String> set) { int size = set.size(); String[] result = new String[size]; Random random = new Random(); int maxNumber = size; Iterator<String> itr = set.iterator(); int resultPos = 0; while(iterator.hasNext()) { result[resultPos++] = itr.next(); } for(int i=0; i<size; i++) { int randomNum1 = random.nextInt(maxNumber); int rnadomNum2 = random.nextInt(maxNumber); String temp = result[randomNumber2]; result[randomNum2] = result[randomNum1]; result[randomNum1] = temp; } return result; } } ``` ```java import java.util.*; import org.openjdk.jmh.annotations.*; @State(Scope.Thread) @BenchmarkMode({ Mode.AverageTime }) @OutputTimeUnit(TimeUnit.MICROSECONDS) public class SetIterate { int LOOP_COUNT = 1000; Set<String> hashSet; Set<String> treeSet; Set<String> linkedHashSet; String data = "abcdefghijklmnopqrstuvwxyz"; String result = null; String[] keys; @Setup(Level.Trial) public void setUp() { hashSet = new HashSet<>(); treeSet = new TreeSet<>(); linkedHashSet = new LinkedHashSet<>(); for(int i=0; i<LOOP_COUNT; i++) { String temp = data + i; hashSet.add(temp); treeSet.add(temp); linkedHashSet.add(temp); } if(keys == null || keys.length != LOOP_COUNT) { keys.RandomKeyUtil.generateRandomSetKeysSwap(hashSet); } } @GenerateMicroBenchmark public void iterateHashSet() { for(String key : keys) { hashSet.contains(key); } } @GenerateMicroBenchmark public void iterateTreeSet() { for(String key : keys) { treeSet.contains(key); } } @GenerateMicroBenchmark public void iterateLinkedHashSet() { for(String key : keys) { linkedHashSet.contains(key); } } } ``` - 결과 | 대상 | 평균 응답 시간 (ms) | | -- | -- | | HashSet | 32 | | TreeSet | 841 | | LinkedHashSet | 32 | - TreeSet 느린 이유 TreeSet 의 속도가 느린 것을 볼 수 있는데 이는 TreeSet 이 데이터를 정렬하면서 저장하기 때문이다. ```java // TreeSet 선언문 public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, java.io.Serializable { ... ``` 구현한 인터페이스 중 `NavigableSet` 이 있는데 이 인터페이스는 크키를 지정하는 메서드를 선언해 놓았다. 즉, 데이터를 순서에 따라 탐색하는 작업이필요할 경우 **TreeSet** 을 사용하는 것이 좋다. ## List **ArrayList**, **Vector**, **LinkedList** 성능 비교 ### ListAdd - 샘플 코드 ```java import java.util.*; import org.openjdk.jmh.annotations.*; @State(Scope.Thread) @BenchmarkMode({ Mode.AverageTime }) @OutputTimeUnit(TimeUnit.MICROSECONDS) public class ListAdd { int LOOP_COUNT = 1000; List<Integer> arrayList; List<Integer> vector; List<Integer> linkedList; @GenerateMicroBenchmark public void addArrayList() { arrayList = new ArrayList<>(); for(int i=0; i<LOOP_COUNT; i++) { arrayList.add(i); } } @GenerateMicroBenchmark public void addVector() { vector = new Vector<>(); for(int i=0; i<LOOP_COUNT; i++) { vector.add(i); } } @GenerateMicroBenchmark public void addLinkedList() { linkedList = new LinkedList<>(); for(int i=0; i<LOOP_COUNT; i++) { linkedList.add(i); } } } ``` - 결과 | 대상 | 평균 응답 시간 (ms) | | -- | -- | | ArrayList | 28 | | Vector | 31 | | LinkedList | 40 | ### ListGet - 샘플 코드 ```java import java.util.*; import org.openjdk.jmh.annotations.*; @State(Scope.Thread) @BenchmarkMode({ Mode.AverageTime }) @OutputTimeUnit(TimeUnit.MICROSECONDS) public class ListGet { int LOOP_COUNT = 1000; List<Integer> arrayList; List<Integer> vector; List<Integer> linkedList; int result = 0; @Setup(Level.Trial) public void setUp() { arrayList = new ArrayList<>(); vector = new Vector<>(); linkedList = new LinkedList<>(); for(int i=0; i<LOOP_COUNT; i++) { arrayList.add(i); vector.add(i); linkedList.add(i); } } @GenerateMicroBenchmark public void getArrayList() { for(int i=0; i<LOOP_COUNT; i++) { result = arrayList.get(i); } } @GenerateMicroBenchmark public void getVector() { for(int i=0; i<LOOP_COUNT; i++) { result = vector.get(i); } } @GenerateMicroBenchmark public void getLinkedList() { for(int i=0; i<LOOP_COUNT; i++) { result = linkedList.get(i); } } @GenerateMicroBenchmark public void getLinkedListPeek() { for(int i=0; i<LOOP_COUNT; i++) { result = linkedList.peek(); } } } ``` - 결과 | 대상 | 평균 응답 시간 (ms) | | -- | -- | | ArrayList | 4 | | Vector | 105 | | LinkedList | 1,512 | | LinkedListPeek | 0.16 | **LinkedList** 가 너무 느린 이유는 *Queue 인터페이스를 상속* 받기 때문이다. 이를 수정하기 위해서는 순차적으로 결과를 받아오는 **peek() 메서드(or poll() 메서드)**를 사용해야 된다. **Vector** 가 **ArrayList** 보다 느린 이유는 동기화 처리가 되어 있기 때문이다. (Vector 의 get() 메서드에 `synchronized` 가 선언 되어 있다.) ### ListRemove - 샘플 코드 ```java import java.util.*; import org.openjdk.jmh.annotations.*; @State(Scope.Thread) @BenchmarkMode({ Mode.AverageTime }) @OutputTimeUnit(TimeUnit.MICROSECONDS) public class ListRemove { int LOOP_COUNT = 1000; List<Integer> arrayList; List<Integer> vector; List<Integer> linkedList; @Setup(Level.Trial) public void setUp() { arrayList = new ArrayList<>(); vector = new Vector<>(); linkedList = new LinkedList<>(); for(int i=0; i<LOOP_COUNT; i++) { arrayList.add(i); vector.add(i); linkedList.add(i); } } // ==== removeFromFirst ==== @GenerateMicroBenchmark public void removeArrayListFromFirst() { List<Integer> list = new ArrayList<>(arrayList); for(int i=0; i<LOOP_COUNT; i++) { list.remove(0); } } @GenerateMicroBenchmark public void removeVectorFromFirst() { List<Integer> vector = new Vector<>(vector); for(int i=0; i<LOOP_COUNT; i++) { vector.remove(0); } } @GenerateMicroBenchmark public void removeLinkedListFromFirst() { List<Integer> temp = new LinkedList<>(linkedList); for(int i=0; i<LOOP_COUNT; i++) { list.remove(0); } } // ==== removeFromFirst ==== @GenerateMicroBenchmark public void removeArrayListFromLast() { List<Integer> list = new ArrayList<>(arrayList); for(int i=LOOP_COUNT-1; i>= 0; i--) { list.remove(i); } } @GenerateMicroBenchmark public void removeVectorFromLast() { List<Integer> vector = new Vector<>(vector); for(int i=LOOP_COUNT-1; i>= 0; i--) { vector.remove(i); } } @GenerateMicroBenchmark public void removeLinkedListFromLast() { List<Integer> temp = new LinkedList<>(linkedList); for(int i=LOOP_COUNT-1; i>= 0; i--) { list.remove(i); } } } ``` - 결과 | 대상 | 평균 응답 시간 (ms) | | -- | -- | | ArrayListFirst | 418 | | ArrayListLast | 146 | | VectorFirst | 687 | | VectorLast | 426 | | LinkedListFirst | 423 | | LinkedListLast | 407 | 결과를 보면 첫번째 값을 삭제하는 메서드와 마지막 값을 삭제할때 LinkedList 는 별 차이가 없지만, 다른 배열들은 메서드의 속도 차이가 크다. ArrayList 나 Vector 는 내부에서 배열을 사용하기 때문인데, 첫번째 값(index: 0)을 삭제하면 두번째 값 부터 (index: 1) 첫번째 부터 처음으로 하나씩 땡겨야 되기 때문이다. (두번째 (index: 1) 값 부터 마지막 값 까지 모두 -1 하여 위치 조정) ## Map Map 은 데이터 추가 작업의 속도가 비슷하므로 get() 메서드만 살펴본다. ### MapGet - 샘플 코드 ```java import java.util.*; import org.openjdk.jmh.annotations.*; @State(Scope.Thread) @BenchmarkMode({ Mode.AverageTime }) @OutputTimeUnit(TimeUnit.MICROSECONDS) public class MapGet { int LOOP_COUNT = 1000; Map<Integer, String> hashMap; Map<Integer, String> hashtable; Map<Integer, String> treeMap; Map<Integer, String> linkedHashMap; int[] keys; @Setup(Level.Trial) public void setUp() { hashMap = new HashMap<>(); hashtable = new hashtable<>(); treeMap = new TreeMap<>(); linkedHashMap = new LinkedhashMap<>(); String data = "abcdefghijklmnopqrstuvwxyz"; for(int i=0; i<LOOP_COUNT; i++) { String temp = data + i; hashMap.put(i, temp); hashtable.put(i, temp); treeMap.put(i, temp); linkedHashMap.put(i, temp); } keys = RandomKeyUtil.generateRandomNumberKeysSwap(LOOP_COUNT); } // ==== sequence map ==== @GenerateMicroBenchmark public void getSeqHashMap() { for(int i=0; i<LOOP_COUNT; i++) { hashMap.get(i); } } @GenerateMicroBenchmark public void getSeqHashtable() { for(int i=0; i<LOOP_COUNT; i++) { hashtable.get(i); } } @GenerateMicroBenchmark public void getSeqTreeMap() { for(int i=0; i<LOOP_COUNT; i++) { treeMap.get(i); } } @GenerateMicroBenchmark public void getSeqLinkedHashMap() { for(int i=0; i<LOOP_COUNT; i++) { linkedHashMap.get(i); } } // ==== random map ==== @GenerateMicroBenchmark public void getRandomHashMap() { for(int i=0; i<LOOP_COUNT; i++) { hashMap.get(keys[i]); } } @GenerateMicroBenchmark public void getRandomHashtable() { for(int i=0; i<LOOP_COUNT; i++) { hashtable.get(keys[i]); } } @GenerateMicroBenchmark public void getRandomTreeMap() { for(int i=0; i<LOOP_COUNT; i++) { treeMap.get(keys[i]); } } @GenerateMicroBenchmark public void getRandomLinkedHashMap() { for(int i=0; i<LOOP_COUNT; i++) { linkedHashMap.get(keys[i]); } } } ``` - 결과 | 대상 | 평균 응답 시간 (ms) | 대상 | 평균 응답 시간 | | -- | -- | -- | -- | | SeqHashMap | 32 | RandomHashMap | 40 | | SeqHashtable | 106 | RandomHashtable | 120 | | SeqLinkedhashMap | 34 | RandomLinkedHashMap | 46 | | SeqTreeMap | 197 | RandomTreeMap | 277 | 대부분 평균 응답 시간이 비슷하지만 TreeMap 클래스가 가장 느린 것으로 보여진다. # 정리 Sun 에서 정리한, 각 인터페이스별로 가장 일반적으로 사용되는 클래스들이다. 필요한 상황에 맞게 사용하면 될 듯 하다. | 인터페이스 | 클래스 | | -- | -- | | Set | HashSet | | List | ArrayList | | Map | HashMap | | Queue | LinkedList | Previous Post 자바 성능 튜닝 - String Next Post 자바 성능 튜닝 - loop (for, while) 성능 향상
